Across India, state government departments are at the forefront of improving human capabilities through education, health, and nutrition programmes. Their ability to do so effectively depends on administrative (or admin) data1 collected and maintained by their staff. This data is collected as part of regular operations and informs both day-to-day decision-making and long-term policy. While policymaking can draw on (reasonably reliable) sample surveys alone, effective implementation of schemes and services requires accurate individual-level admin data. However, unreliable admin data can be a severe constraint, forcing bureaucrats to rely on intuition, experience, and informed guesses. Improving the reliability of admin data can greatly enhance state capacity, thereby improving governance and citizen outcomes.
There has been some progress on this front in recent years. For instance, the Jan Dhan-Aadhaar-Mobile (JAM) trinity has significantly improved direct benefit transfer (DBT) mechanisms by ensuring that certain recipient data is reliable. However, challenges remain in accurately capturing the well-being of targeted citizens. Despite significant investments in the digitisation of data collection and management systems, persistent reliability issues undermine the government’s efforts to build a data-driven decision-making culture.
House of sticks
There is growing evidence of serious quality issues in admin data. At CEGIS, we have conducted extensive analyses of admin data across multiple states, uncovering systemic issues in key indicators across sectors and platforms. These quality issues compound over time, undermining both micro-level service delivery and macro-level policy planning. This results in distorted budget allocations, gaps in service provision, and weakened frontline accountability. Consider the following examples:

1. Learning outcomes
Independent re-evaluation of the learning outcomes recorded by government schoolteachers in standardised tests across two Indian states suggests that admin data is substantially exaggerated. In one state, the proportion of correct responses reported in the admin data was, on average, 39 percentage points higher in maths and 34 percentage points higher in language.
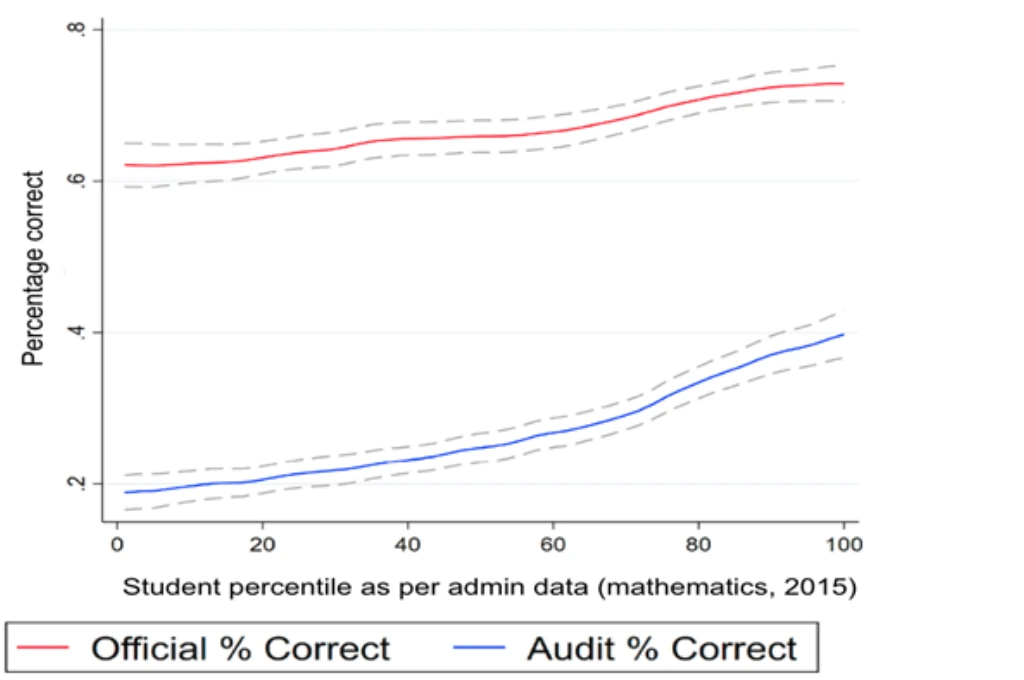
Such misreporting a) hides the severity of the learning crisis, potentially delaying timely policy responses; b) makes it difficult for bureaucrats to identify and support low-performing schools, or recognise high performers; and c) prevents individual children in a classroom from receiving the academic support they need.
2. High-risk pregnancies (HRPs)
The true rate of HRPs is estimated to be five to ten times higher than what admin data suggests. Contrast the percentage of pregnant women identified as HRP using data from the National Family Health Survey (NFHS)-5 (considered independent) with data from the Health Management Information System (maintained by the Ministry of Health and Family Welfare and considered as admin data). We find that in several states and union territories (UTs), the recorded percentage of HRPs is 35 to 45 percentage points lower than independent estimates. This translates to 1–2 lakh HRPs going unidentified2 in each state.
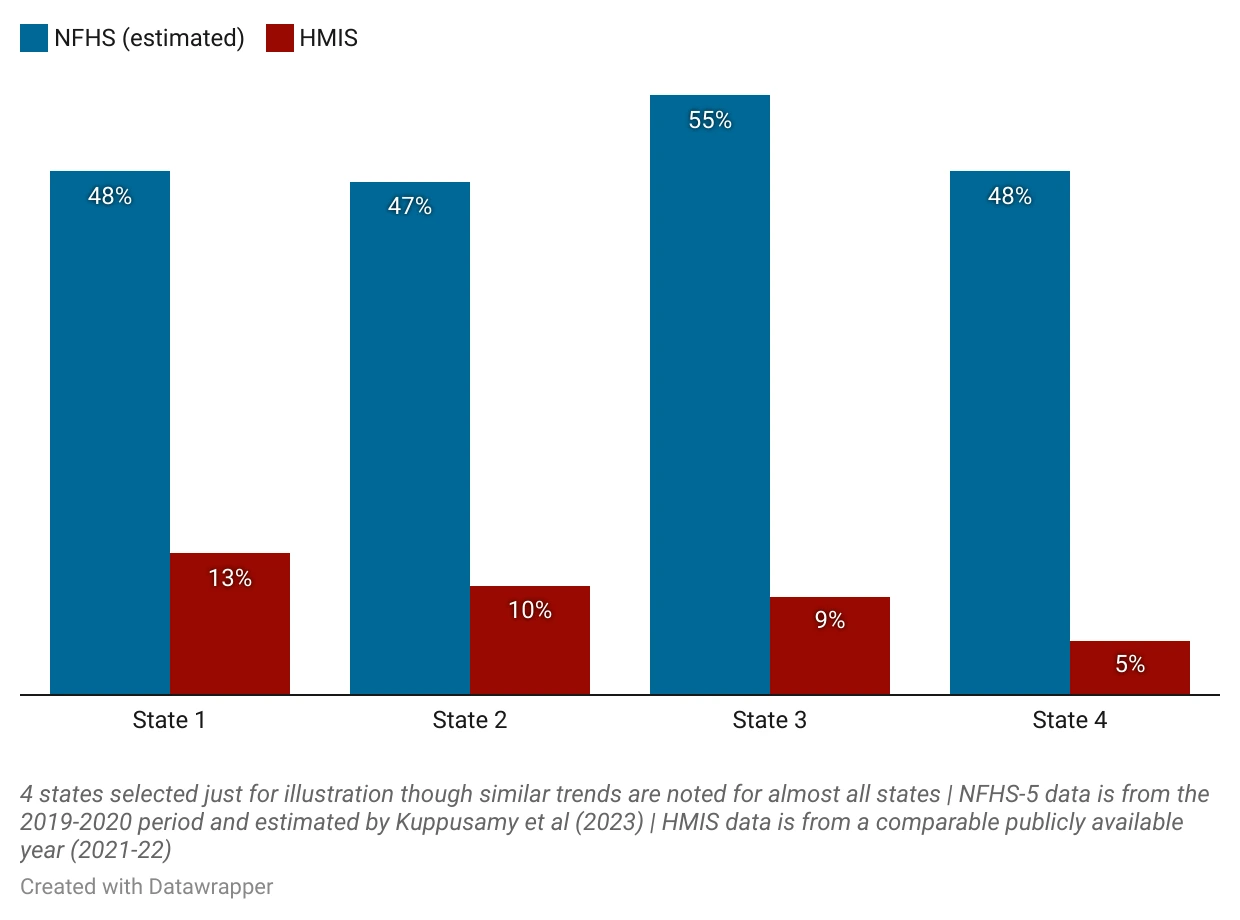
The non-identification of HRPs can prove fatal for pregnant women and their children, contributing to higher infant and maternal mortality rates. It also imposes immediate costs on both citizens and the government, as late detection substantially increases the cost of care at the time of delivery.
Overall, the repercussions of unreliable admin data are particularly high in areas such as education and health. Imagine the consequences when the high-risk status of a pregnant woman or a student’s inability to read goes unrecorded. The window for corrective action is very narrow, and not addressing these issues early has an enduring negative impact on an individual’s well-being.

Not everything that gets measured gets ‘managed’
Several interrelated factors contribute to the persistence of unreliable admin data.
1. Data collection is time-consuming
One major issue lies in the burdensome data collection workflows imposed on frontline staff, who often have to spend an inordinate amount of time on data entry. For example, an average Anganwadi worker spends approximately one-fifth of each working day entering data in multiple paper registers and mobile apps. Paper reigns supreme, as digital apps are both hard to use and change without notice. Mismatches between data requirements of the state and centre add to their workload.
The culprit is often the design of data collection workflows. Overburdened staff are expected to juggle service delivery with extensive documentation requirements, leading to rushed data entry, unchecked assumptions, and, at times, outright fabrication. Senior officials, perhaps unaware or untrusting of existing data, repeatedly ask staff to collect data on the same indicators. As a result, reliability takes a backseat to compliance.
2. Measurement is complex
Another challenge lies in the complexity of measurement itself. Indicators such as a baby’s weight or a first-grader’s numeracy skills require adherence to standardised protocols, and sometimes, specialised equipment. So, when a large number of frontline staff are tasked with carrying out these measurements at scale, frequently, and with very little training, the quality suffers. Even if these structural issues were addressed, the absence of data-driven oversight mechanisms allows reliability issues to persist unchecked.
3. Quality control remains lacking
Despite real-time data flowing in from the frontline, most states lack systems to flag outliers or suspicious patterns. These checks could reduce the need for corrections post data entry. Back-checks and spot-checks are uncommon, as the status quo within most departments is for supervisory officials to conduct intermittent, inspection-style visits that are often unstructured. For instance, a supervisor working in Integrated Child Development Services typically visits an Anganwadi centre only about once in a quarter, as they are responsible for 26 centres on average. Even in states where unstructured visits are conducted properly, data from these visits is not used to study data quality.
4. Data literacy is scarce
Lastly, much like frontline staff, supervisors often lack strong data competencies or literacy, which limits their ability to identify and correct errors. Since they may not have the skills to analyse patterns or detect inconsistencies, they rarely scrutinise the reliability of the data they receive. As a result, their feedback to frontline workers tends to focus on meeting reporting requirements rather than improving data accuracy. Beyond the department, there is a dearth of independent data checks, leaving little incentive for frontline staff to prioritise reliability. Despite substantial budget allocation and guidelines, many states do not conduct regular social audits of education and health services.
Misaligned incentives devalue data reliability at both individual and systemic levels. A clear conflict of interest arises when frontline service providers are responsible for reporting their own performance. The pressure to meet predefined targets or demonstrate programme success often leads to data manipulation, either through exaggeration of successes or suppression of negative outcomes.
For example, more than one-third of the growth measurements of children under five at Anganwadis in a medium-sized Indian state were recorded just within 1 kg of the wasting threshold. In other words, if such a child’s weight had been recorded even a few hundred grams lower, they would have been classified as moderately malnourished. This classification would have triggered additional care duties and potentially a hospital referral by the Anganwadi worker. Assuming that true malnourishment rates are very high, such stark spikes at critical action thresholds are suspicious.
Anecdotal evidence supports this, with frontline staff confessing to misreporting data to avoid getting pulled up by their superiors in meetings, facing pressure from seniors to not present the department in an unfavourable light, and, most consequentially, avoid being assigned extra work since recording a ‘poor’ outcome makes them directly responsible for the corrective action.

Building a house of bricks
At CEGIS, we advocate for a mindful measurement system that goes beyond digitisation. Given the foundational value of reliable data, a holistic, multi-pronged strategy is required.
1. Rethinking processes and leveraging technology
Re-engineering processes and embedding technology at the source would simplify workflows and significantly reduce human errors. For example, testing student learning using tablets generates reliable data and is found to be cost-effective compared to paper-based testing. Thus, cost-effective technology can be used to free up time of the frontline staff from data entry to focus on delivering quality services. When technology is ill-suited to the ground reality, the optimisation of paper-based, manual workflows can yield substantial gains. For example, if each teacher is saved from having to carry out data entry tasks for 10 days per year, expenditure worth INR 623 crore per year per state could be put to more effective use.
Further, several states are undertaking drives to replace and/or calibrate existing equipment. Use of technology such as AI-enabled apps and remote sensing can remove the dependency on frontline staff for data entry. It is also important to modify on-paper rules, responsibilities, and other compliance matters to ensure that optimised workflows are not treated as double work by staff and that redundancies are truly removed.
Additionally, strengthening data-driven supervision using technology and statistics can enhance the quality and quantity of interactions between frontline staff, citizens, and supervisory officials. Data from visits, coupled with automated data checks, enables a tight feedback loop to ensure discrepancies are identified and corrected promptly. Community participation through social audits can be fostered to encourage transparency and increase citizen ownership.
2. Eliminating dependence on punitive responses
Conventional reliance on punitive measures often fails to address the underlying motivations behind unreliable data. Behavioural insights can offer alternative strategies. For instance, highlighting real-world consequences of inaccurate data—such as a vulnerable child being denied services—can serve as an emotional trigger that reinforces the value of reliability. At the system level, incentives change when data reliability is given weight in performance rankings. In this way, staff members are rewarded for reporting the truth.
Overall, improving data reliability in a holistic manner requires enhancing individual motivation and aligning systemic incentives to value data reliability and reinforce the use of accurate data.
—
Footnotes:
- While administrative data refers to all the data maintained by the departments—such as information on personnel, finances, services, processes, and infrastructure—in this article, we use the term to specifically refer to data on individuals eligible for schemes and the outcomes of these programmes.
- Consider a state with an estimated 3 to 5 lakh pregnant women per year. If the gap between independent estimates and admin data ranges between 35 and 45 percent, then the number of unidentified HRP cases will be somewhere between 1,04,700 (35 percent of 3 lakh) and 2,26,450 (45 percent of 5 lakh).
Know more
- Read this article on the importance of administrative data for evidence-based policy-making.
- Learn more about data-driven governance.
Do more
- Contact the authors at ganesh@cegis.org and parul@cegis.org to learn more about the tool CEGIS is creating to measure data quality.