Many social sector organizations see the transformative potential of AI and are inviting IDinsight to support them in deploying it to improve lives in different ways, from helping community health workers more easily diagnose patients, to identifying vulnerable households most in need of cash assistance.
We’ve observed that many organizations in the sector are struggling to fully realize the promise of AI not because the technology itself is lacking, but because their underlying data infrastructure isn’t in place. AI is only as powerful as the data that fuels it. While basic interactions with tools like ChatGPT can be insightful, more strategic and high-value use cases such as asking, “Which of my community health workers need support?” require structured, connected data: who you are, who’s on your team, and the real-time status of their work. Without this infrastructure, AI insights remain shallow and generic.
By investing in data infrastructure, organizations can open up advanced applications of AI to drive organizational transformation and improve lives.

Data infrastructure refers to the systems that can automatically and reliably extract raw data from different sources (frontline worker apps, financial management systems, field data collection tools, etc.), clean and store it, and make it available in a predictable format to the AI tools that need to use it. Robust data infrastructure also requires people, policy, and processes to ensure data is high quality, well documented, and securely accessed only for authorized purposes. Common components of data infrastructure include data warehouses, data lakes, data pipelines, and data catalogs.
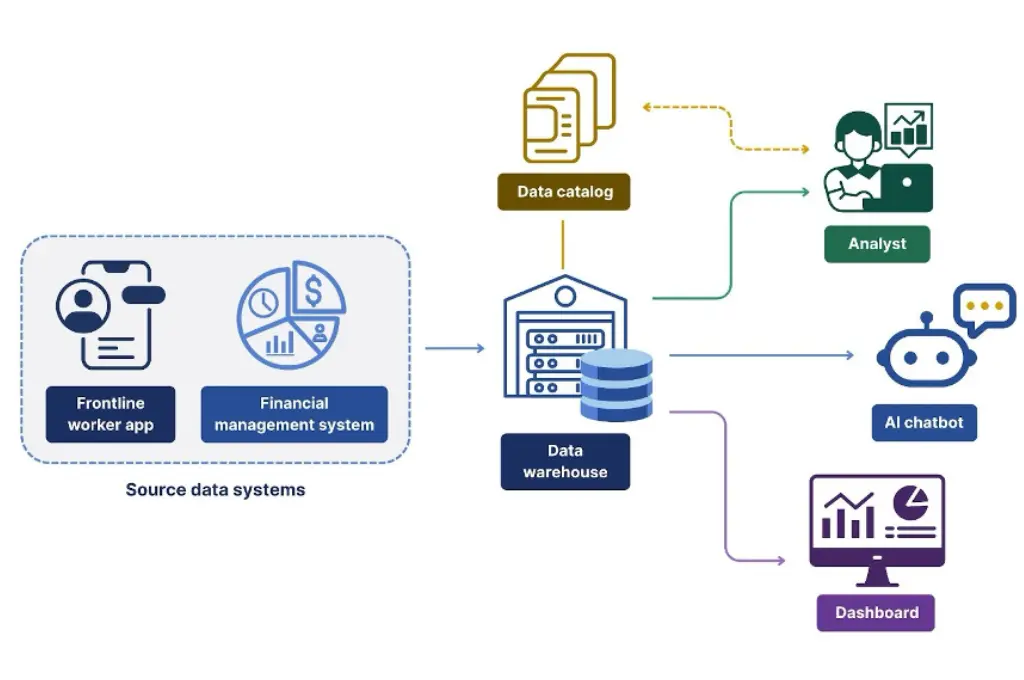
How data infrastructure unlocks specific AI use cases
Conversational business intelligence
AI-powered tools now allow users to ask natural language questions of their data (“What’s our dropout rate by district this year compared to last?”) and get instant answers. But these tools only work if the underlying data exists and is clean, well-structured, and thoroughly documented.
Large language models (LLMs) in particular need rich metadata to understand what fields mean, how they relate, and how to query them. Organizations also need a “semantic layer”: a shared set of business definitions that codify all the little judgment calls that need to be taken when trying to draw insights from the data (e.g., when a contract is renewed, do we count that as one contract or two for the purposes of counting “Total contracts”? When asking how many beneficiaries were active in a given month, does that mean people who accessed services in that month, during some set amount of time prior to that month, or another definition entirely?). These decisions may seem trivial, but they can have large impacts on how the data gets interpreted, and without agreed-upon standards metrics become inconsistent and trust in the system erodes.
AI chatbots
Many social sector organizations are deploying AI chatbots to answer staff, partner, or beneficiary questions. At a basic level, chatbots can be powered by static knowledge bases, like documents and FAQs, that don’t change much over time. But as soon as an organization needs the chatbot to reflect frequently updated information (such as changes to benefits levels or eligibility criteria for government social programs) the complexity increases dramatically. That requires robust pipelines to frequently refresh the knowledge base, ensure accuracy, and prevent outdated or misleading responses.
Prediction with machine learning
Predictive analytics can help organizations identify at-risk students, forecast medicine stockouts, or target social protection benefits. But building reliable predictive models requires more than algorithms. Historical data must be carefully preserved, with consistent definitions for features (the data points we’ll use to predict our outcomes of interest) and labels (the outcomes we want to predict). Predictive models also tend to become less accurate over time due to data drift (when we encounter data different from what the model was trained on, for example, an organization starts serving a new population of beneficiaries) and model drift (when the state of the world changes due to changing economic realities, new government regulations, etc.). Without ongoing monitoring and feedback loops, predictive models can slowly degrade and lose their value.


This isn’t just a problem for AI
The value of data infrastructure isn’t new and isn’t unique to AI.
- Dashboards and data visualization: For years, governments and NGOs have aspired to build ambitious dashboards, like 360-degree beneficiary views. But this is easier said than done. While some of these bottlenecks are institutional and governance related, sharing data across departments and interoperability remain stubborn hurdles.
- A/B testing for program design: A/B tests are a powerful way to improve social programs. Yet if data processes are highly manual, test results can be delayed, slowing down an organization’s ability to learn and adapt.
What’s needed
Good data doesn’t just happen. It requires deliberate investments in infrastructure and strong collaboration across the entire data lifecycle:
- Collection and capture – ensuring frontline staff and systems gather the right data, consistently.
- Data engineering – building pipelines to ingest and process the data and ensure it’s usable by both analysts and applications.
- Analysis and data science – deriving insights and building AI solutions on a trustworthy foundation.
- Data use – empowering end users to make meaningful decisions using the data.
This is as much an organizational and leadership challenge as it is a technical one. Building data infrastructure that lasts requires vision, coordination, and buy-in across teams. From a funder perspective, this means intentionally investing in the underlying data systems that will support data use across an organization including AI, monitoring and reporting, and A/B testing. By prioritizing cohesive systems over fragmented efforts, organizations can unlock greater impact, reduce duplication, and build a stronger foundation for future innovation. Data is a powerful driver of progress when it’s treated as a strategic asset rather than an afterthought.
This article was originally published on IDinsight.



